Benchmarking
Once you have sized the cluster based on the expected numbers, it is time to validate whether it can meet the performance requirements.
Running benchmarks are helpful, but it is key to monitoring your cluster to understand the effect. We will use Grafana to monitor the cluster. The following metrics are important:
CPU - CPU cycles are required for query handling (parsing, planning, executing queries) and indexing data. CPU utilization of around 90% is a good first indicator that the cluster is well utilized. But looking at CPU usage alone can be misleading, as there is a fine line between well-utilizing and overloading the cluster
Memory usage. RAM
Thread pool—In CrateDB, each node has several thread pools for different operations, such as reading and writing data. Each thread pool has a fixed number of threads that process operations. If no free thread is available, requests are rejected, and operations are queued.
Number of active write threads
Ingest Benchmark
We will use the nodeIngestBench to benchmark the ingest. It is a multi-process Node.js script that runs high-performance ingest benchmarks on CrateDB. It uses a data model adapted from Timescale's Time Series Benchmark Suite (TSBS). One of the reasons to use nodeIngestBench is the fact that it is easy to configure and change variables like:
batchsize:The number of rows passed in a single INSERT statement. The higher the number, the fewer inserts you must perform to ingest the generated data. At the same time, there comes the point of diminishing returns.max_rows:The maximum number of rows that will be generated. This is the parameter that allows the control of the total runtime of the benchmark.shards:The number of shards the table will be split into. Each shard can be written independently, so we aim for a number that allows enough concurrency.concurrent_requests:The number of INSERT statements that each child process will run concurrently as asynchronous operations.processes:The main node process will start this number of parallel child processes (workers) that generate INSERT statements.replicas:Replicas are pretty much pointless on single-node clusters. On multi-node clusters, however, they provide a great way to avoid data loss in case of node failure. For the 3-node cluster, we created one replica.
There are a couple of angles here.
The first is to see if the cluster can handle the projected workload.
Find the sweet spot where the cluster can handle the workload with the lowest impact on resources. This is about finding the optimal balance between the number of shards, the batch size, the number of processes, and other factors.
Then, there is finding the limits of the current cluster. When does the curve flatten?
Environment
We use a three-node CR2 CrateDB Cloud Cluster in Azure EU-WEST for the benchmark exercise. a CR2 cluster has the following configuration for each node:
4 vCPU
14 GiB RAM
32 GiB SSD Storage
These are per-node resources. When deploying multi-node clusters, multiply these by the number of nodes. Storage is a big part of fast writing. Offered storage depends on the tier of the cluster, but in general, we offer storage of up to 8 TiB of enterprise-level SSD per node.
For the ingesting tool/benchmark VM, we decided on the Standard_D48_v3**. **We don't need all 48 CPUs this instance offers, but it's the most affordable instance with 24 Gigabit networking, which can be necessary when ingesting into higher-tier CrateDB Cloud clusters.
Deploy nodeIngestBench
Install Node.js using one of the available installation methods
Clone this repository:
git clone https://github.com/proddata/nodeIngestBench.gitChange into the cloned repository:
cd nodeIngestBenchInstall dependencies:
npm installConfigure the connection to your CrateDB cluster by creating a
.envfile:
Run a quick test to see if you can connect.
If this is successful, then you are set to start benchmarking.
nodeIngestBench will create a table doc.cpu that has the following structure:
Install & Configure Grafana
A Grafana OSS (docker) container is deployed on the ingest VM for this test. However, if Grafana is already running in your environment, you can skip this installation step.
For further details on how to set up and connect Grafana to CrateDB Cloud or your self-managed cluster, see this blog post.
For this blog, we used the following Grafana Dashboard that can be imported into Grafana.
Running Ingest Benchmarks
Once the prerequisites are met, you can start benchmarking. You can define your own set of tests to match your specific needs.
All the tests below are executed using:
1 Million rows
This will result in a data volume of:
166 MiB
This is the number of data for the primary shards. When using replicas, this will, of course, affect the data volume. Total size = ‘data volume’ x #replicas
The AVG row size of this table is:
166 MiB = 166 × 1024 × 1024 bytes = 174,063,616 bytes
Note: These tests below were executed with a replica of 1.
Find the optimal batch size
We need to run several tests to determine the optimal batch size. You can do this manually or use a script like this one, which loops through different batch sizes and reports the results in an output file.
You should monitor Grafana during the execution to see its impact. On my cluster (3 x CR2), we see this impact.

Putting the numbers of this into a table, we end up with this:
500
184.433
1,000,000
5,422.023
0
1000
101.466
1,000,000
9,855.518
81.77%
2000
59.838
1,000,000
16,711.789
69.57%
4000
39.030
1,000,000
25,621.317
53.31%
8000
27.812
1,000,000
35,955.703
40.34%
16000
22.712
1,008,000
44,381.825
23.42%
32000
20.024
1,024,000
51,138.634
15.22%
You can see that the curve, looking at the speed increase, is flattening.

Find the optimal number of shards.
To find the optimal number of shards for this cluster, we must run tests with different sizes to find the sweet spot.
You can run that manually or use a script like this one that loops through different numbers of shards and reports the results in an output file.
You should monitor Grafana during the execution to see its impact. On my cluster (3 x CR2), we see this impact.

This is the outcome of the find-optimal-shards.sh execution.
3
32,702.852
0
9
43,812.753
33.97%
12
45,901.639
4.77%
18
44,663.033
-2.70%
36
44,334.975
-0.73%
54
40,173.767
-9.39%

The sweet spot for the number of shards in this cluster and dataset is 12, which is one shard per vCPU in the cluster.
Find the optimal number of clients (processes)
Besides shards and batch sizes, knowing the optimal number of clients can also be beneficial. Execute nodeIngestBench, with different amounts of processes, to find the optimal number for your cluster.
You can run that manually or use a script like this one that loops through different numbers of shards and reports the results in an output file.
You should monitor Grafana during the execution to see its impact. On my cluster (3 x CR2), we see this impact.

You can see that the increasing number of processes affects both the CPU usage (the reason you know the CPU going above 100% has to do with the fact that the CrateDB Cloud cluster runs in Kubernetes and allows for CPU bursting for pods using CPU limits. If a pod gets extra CPU time beyond requests, the value can exceed 100%. But you also see that the number of rejected writes in the thread pool is increasing. Looking at the output of the benchmark run, the first number of rejected writes in the thread pool starts when using 48 processes. This is something you want to prevent!
Looking at the run's output, you can see the improvement you get when using three processes instead of one, but also that after two processes per node, you will see a diminishment in performance.
1
44,015.545
-
3
108,441.512
146.37%
6
138,839.788
28.03%
12
106,305.752
-23.43%
24
93,549.522
-12.00%
48
65,006.745
-30.49%
Find the cluster saturation point.
When benchmarking a distributed database like CrateDB, cluster saturation is one of the key performance thresholds you'll encounter. It occurs when your cluster reaches its maximum capacity—whether due to CPU constraints, memory pressure, disk I/O bottlenecks, or network congestion—leading to diminishing performance returns as additional queries or workloads are introduced.
Saturation is a critical point in performance testing because it defines the system's operational limits. Identifying it early helps with capacity planning, tuning configurations, and determining when to scale horizontally.
To find the saturation point, we will ramp the number of rows whilst keeping the optimal sizes found during the previous exercises.

Looking at the Grafana dashboard, you don't see a problem directly, but the decrease in speed for the run with 32 million rows indicates that something is slowing the ingest down.
1,000,000
108,352.144
-
2,000,000
105,529.759
-2.60%
4,000,000
97,637.180
-7.48%
8,000,000
97,551.458
-0.09%
16,000,000
95,754.294
-1.84%
32,000,000
75,474.309
-21.15%
Looking at the File System Writes, you can see that after 30 minutes, the performance goes down to around 25MB/s. We used small disks (32GiB) for this performance test with a standard throughput of 25 MB/sec with 30 minutes of bursting. In this case, the bottleneck Is the disk throughput. With large disks, we will get more IOPS and more throughput.

Query Benchmarking
We use Locust to run load tests using a customizable set of SQL statements. It is a great, flexible, open-source (Python) framework that can swarm the database with users and obtain the RPS (request per second) for different queries.
Setup Locust
Installing Locust is easy. Please execute the following to install it on the same box tool/benchmark VM you use to execute nodeIngestBench.
pip3 install -U locust crate
To run Locust and execute queries, you will need to create a file named locustfile.py
You can use this as a starting point. It will be configured to run queries against the same table created by running nodeIngestBench.
In addition to the pure Locust execution, it contains a CrateDB-specific implementation. Instead of a plain HTTP client, it connects to CrateDB using our Python driver.
Configured Queries
In this example locustfile, there are in total 6 different queries. See the underlying table.
Max User CPU per Datacenter
Gets max user CPU per data center.
Aggregation
2
34.31
Point Query - Latest CPU Metrics
Fetches the latest CPU metrics for a specific host.
Point Query
10
2707.98
Point Query - Specific Service
Gets the latest CPU data for a random service environment.
Point Query
9
1500.00
Point Query - Recent CPU Snapshot
Gets the most recent CPU snapshot for a host.
Point Query
8
4.89
Point Query - High CPU Hosts
Finds hosts with usage_user greater than 80.
Point Query
7
2000.00
Moving Avg User CPU (Datacenter Filter)
Computes the moving average of user CPU in the data center.
Window Function
1
76488.4
The Weight value in Locust determines how frequently a specific task (query) runs relative to other tasks. It balances the load between lightweight and heavyweight queries.
Higher Weight → More Frequent Execution
A task with a higher weight will be executed more often, increasing its share of the total requests.
Lower Weight → Less Frequent Execution
A lower weight means the task will be called less frequently, usually for heavier or more resource-intensive queries.
For example, If you have:
Point Query - Latest CPU Metrics with weight 10, and
Moving Avg User CPU (Datacenter Filter) with weight 2,
Locust will run the point query 5 times more often than the window function query.
Query Benchmark - Using Locust
You can start running Locust using the example queries from the blog. Start by doing a small number of users and gradually ramp up to see the effect on resource consumption. This example locustfile is built so that the operations/sec will be ~ equal to the number of users. So, if you estimate 50 queries per second, you can ramp up to 50 users and see how it affects both response times and resource consumption.
You should run Locust first to see if everything is working and, therefore, configured correctly. After this, the goal is to run both the ingests using nodeIngestBench and Locust to understand their impact.
Start Locust
Once the locust.py is configured, you can start running Locust. Suppose you want to run a locust with multiple processes. In that case, you can start Locust by specifying --processes or using -1 to autodetect the number of logical cores in your machine and launch one worker per vCPU.
In my case, I'm starting Locust with 8 processes, so I have some additional processes that can run the ingest simultaneously.
Connect to the locust web interface at port 8089. When starting a new load test, specify the number of users (peak concurrency), the rampup, and the host. The host will be the end-point, so it is your CrateDB cluster in this case. Under Advanced options, you can specify the runtime. In this case, I leave it blank because I want to be in charge of stopping or ramping up.

Click start to kick off the first run. After the configure clients are started we should see something like this.

In the aggregated row, you should see ~50 RPS, the same as the number of configured users. That, in combination with zero failures, means that Locust Is running as it should, and you are ready to start benchmarking.
Let's see what the effect is on the load on the cluster using Grafana.

Queries + Ingest
Let's add the ingest to the mix. As nodeIngestBench is designed to push maximally, running a while loop like this one is advised. With max_rows < 16000, please use the same batch_size as the max_row. That way, you can control the rows per second. In this case, it will run 1000 ingests per second, which can easily be changed to more rows per second.
In Locust, we see that the throughput is still at 50 queries/sec.

Both the 50th and 95th percentiles fluctuate a bit more than before. In Grafana, we see an increase in CPU usage, which is to be expected, but the load is still good.
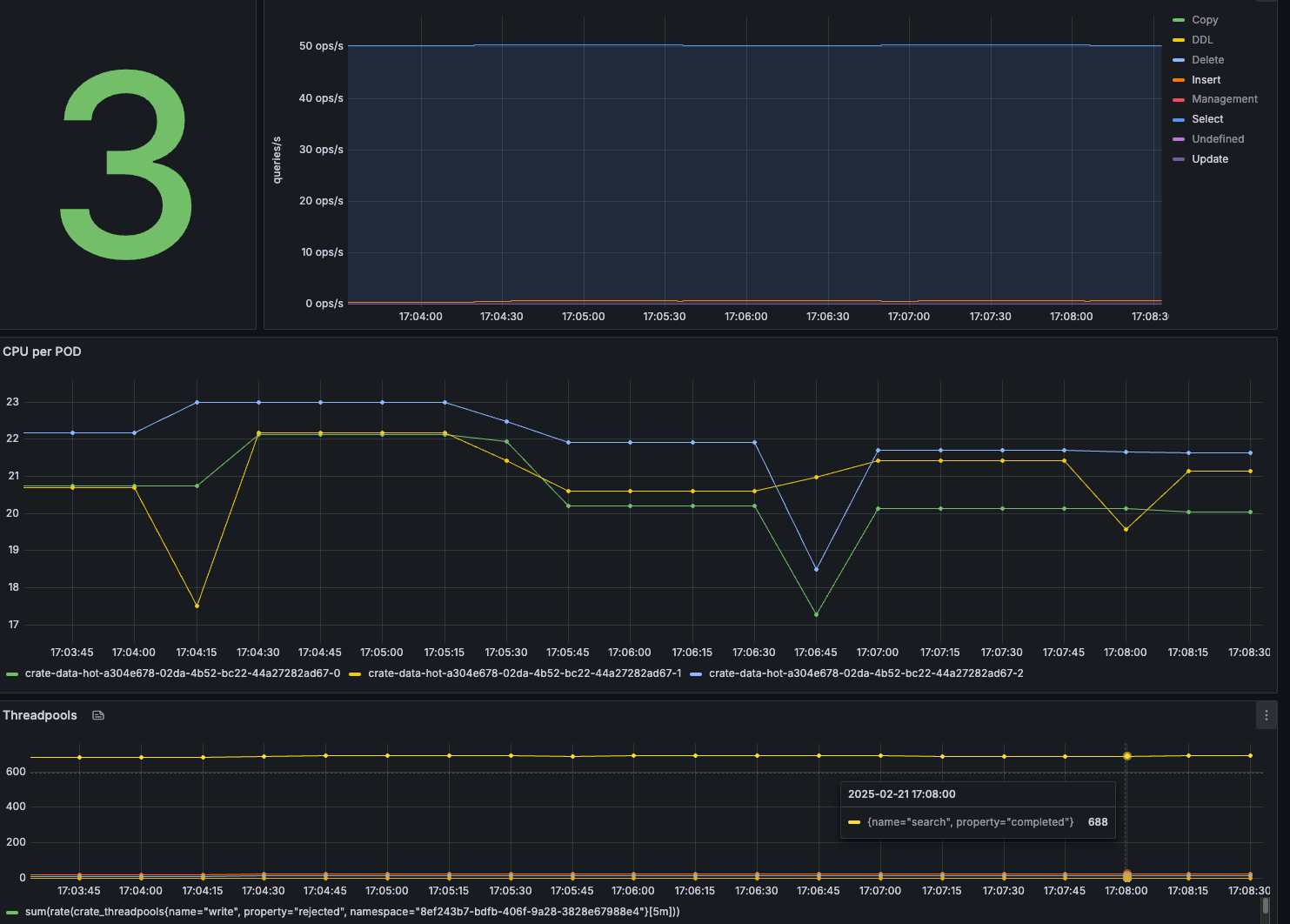
Ramp up - 100 Queries/sec.
While keeping 1000 rows/sec, let's double the number of queries by increasing the number of users in Locust to 100.

Look at the performance graphs in Grafana to see the load on the cluster.

Ramp up - 150 Queries/sec
While keeping the ingest at 1000 rows per second, we will gradually increase the number of queries per second to see the effect. In this case, we will add one user per second.

After some time, we saw that all the users had been spawned, and 150 queries/second had been executed.

In the chars view in Locust, the RPS is ~ 150, with 0 failures.

In Grafana, we see CPU between 55% and 65%. There is no rejection in the thread pool, so everything is still good!

Ramp up - 200 Queries/sec

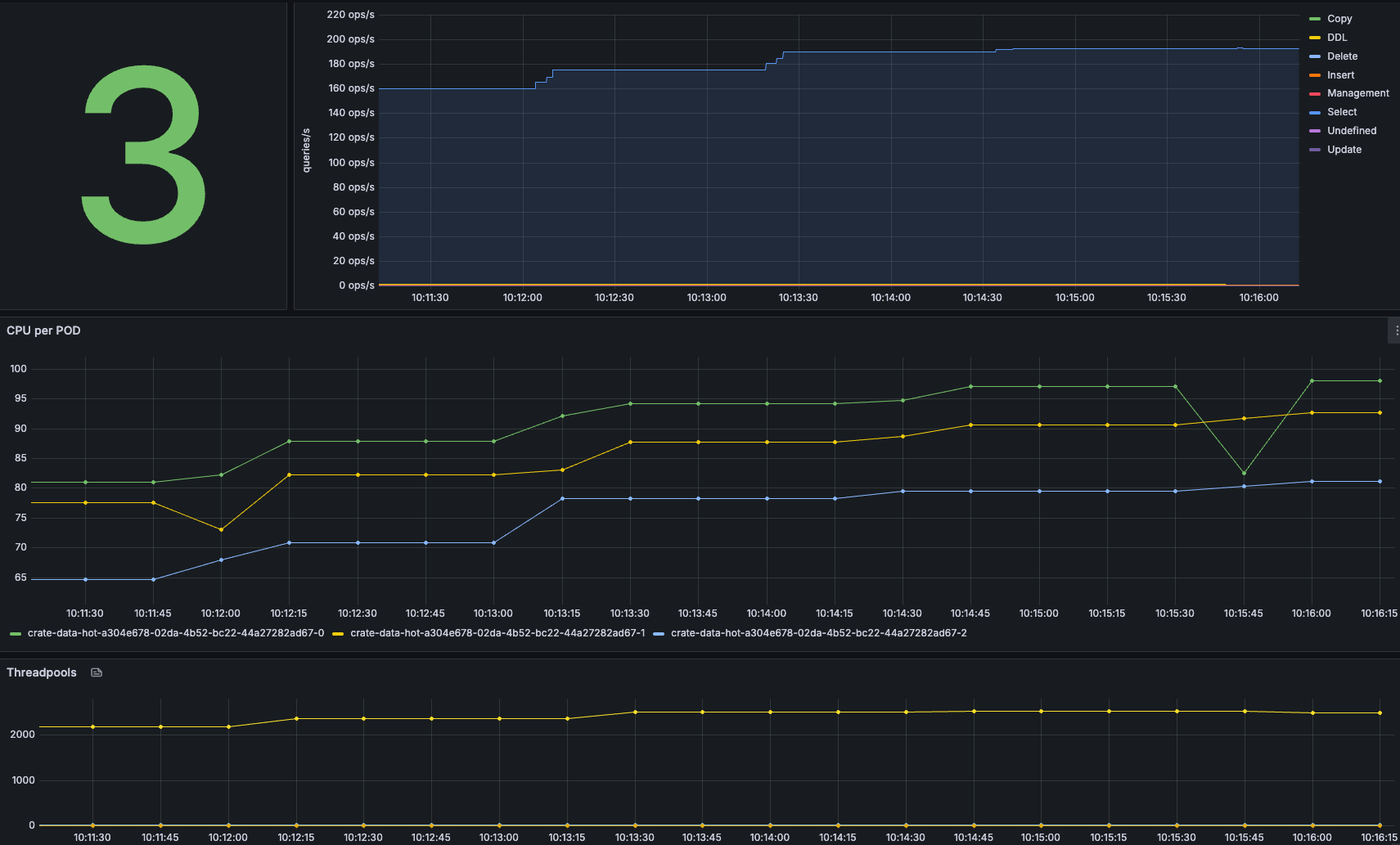
Looking at the cluster and the load, it becomes clear that even with 200 OPS/sec, the cluster is busy but stable! As soon as the graphs in Locust become flaky, you know you are reaching the limits of your cluster.
The Locust charts show that the RPS line is no longer flat but that the number of queries/sec starts to fluctuate more, indicating that the cluster is under more pressure than before.

Conclusion
When deploying CrateDB (or any distributed database), assumptions about performance and scalability are never enough—they must be validated through rigorous benchmarking. Estimating cluster size, optimizing shard configurations, and fine-tuning parameters are crucial first steps, but only real-world testing can reveal actual system behavior under load.
By systematically running ingest and query benchmarks, we:
✅ Identify performance bottlenecks (e.g., CPU saturation, disk I/O limits, or inefficient sharding). ✅ Find the "sweet spot" for batch sizes, shard counts, and concurrency settings. ✅ Determine system limits and when to scale before hitting production issues. ✅ Ensure cost efficiency by using only the necessary resources for the expected workload.
Performance tuning is an iterative process. Benchmark, monitor, adjust, and repeat—this is the only way to ensure your CrateDB deployment runs efficiently, reliably, and cost-effectively at scale. Don't guess—test!
Last updated